This resource is designed to engage your participants in learning about patterns and algebraic thinking. The activities are similar to those your participants can use in teaching children, but are more complex and demanding. The basic idea, (one often used in teacher workshops) is to help your participants gain some insight into the challenges children face in learning about patterns and algebra, as well as to explore different representations of the same pattern.
Revised November 8, 2018
Activity for Teacher Educators
Mathematics involves looking for patterns and regularity in many domains, including number, shape, and space. So, even though many of us associate algebra with secondary education, patterns and algebraic thinking are important for young children’s math learning as well. Review What Young Children Know and Need to Learn about Patterns and Algebraic Thinking for more information on how children develop algebraic understanding.
In the activity that follows, participants will explore how to examine patterns and use rules to describe them.
Materials
The only materials needed for this activity are something to write on (paper or whiteboards), something to write with (pencils or markers), and the Toothpick Patterns PowerPoint, which is at the end of this handout.
Activity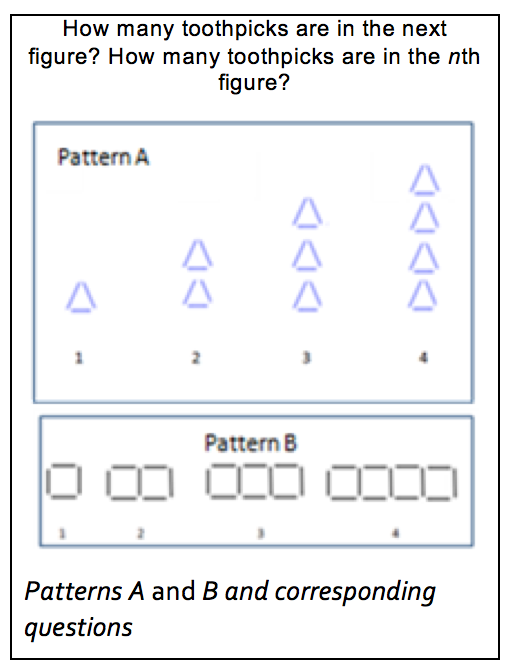
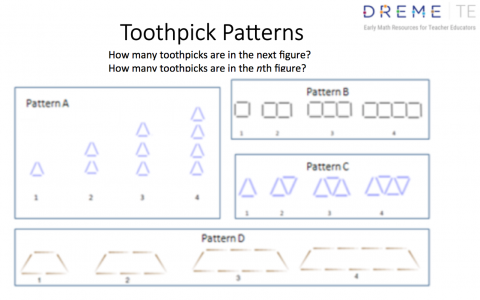
In the activity, participants work in small groups. Present the first two of the four patterns (A and B) in the PowerPoint slide. They are also shown here.
Each pattern shows figures made using toothpicks. Each figure is labeled with a number showing its position in the pattern. Ask participants to determine the number of toothpicks needed to create the next figure (the 5th figure in Patterns A and B) and the nth figure in each pattern. Explain that these patterns would not be appropriate for children. They are meant to be challenging for adult learners to tackle, but not impossible to explore and solve, at least partially.
Encourage participants to approach and represent Patterns A and B however they wish. Circulate among the groups to see how participants tackle the task. Some may start working individually while others may begin by having discussions with others in their group. To see a detailed example of how this activity played out in a university mathematical development course, see Teaching Algebraic Thinking to Young Children: In Action.
Pay particular attention to how participants represent the patterns. They may draw the figures in the patterns and write numbers next to them. They may create tables. The representations they choose may help them see that the patterns are related. For example, Pattern A consists of triangles formed by toothpicks and Pattern B consists of rectangles formed by toothpicks. Visually, they do not look similar. However, in both patterns, each new figure is formed by adding 3 more toothpicks to the previous figure.
Discuss what the participants notice. Ask them to reflect on what it was like to find the rules. This can be a very challenging task for participants who worry about their mathematics understanding and skill. Creating an environment where ideas are discussed and partial solutions are valued will help participants feel more comfortable and willing to engage and share ideas.
What to Look for in Participant Responses
Note that participants could focus on recursive rules or algebraic rules. By recursive rule, we mean a rule that shows how to find the next figure if you know the previous one. Thus, Patterns A and B involve adding 3 toothpicks to each figure to form the next figure. By algebraic rule, we mean a more general rule that could be used to find any figure in the pattern ─ the nth figure.
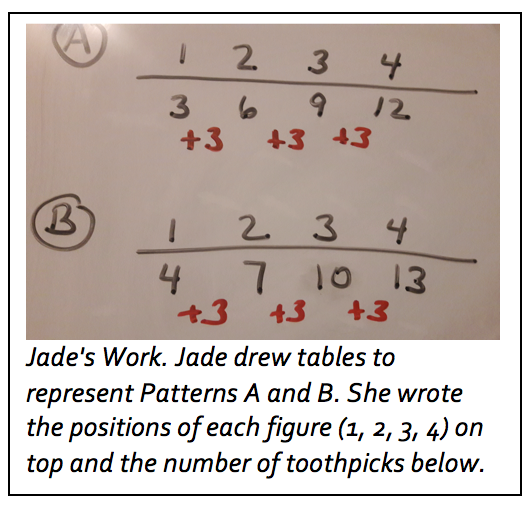
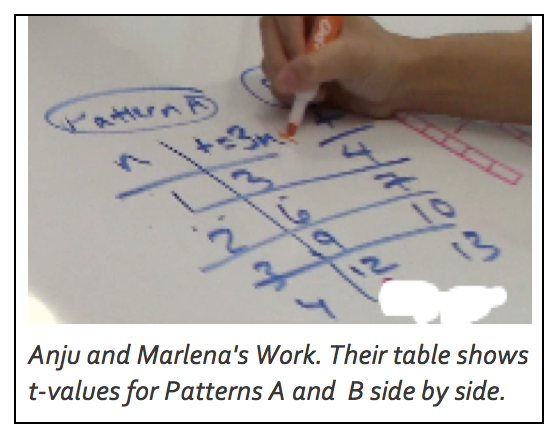 Most participants will notice the recursive rule first. They may describe the rule as “+3” or “add 3.” The challenge for participants may be moving from the recursive rule to the algebraic rule. The recursive rule involves adding 3 to get the next number in the pattern, but the algebraic rule involves multiplying the position number, n, by 3. For example, figure 2 in Pattern A is made up of 2 triangles each with 3 toothpicks, so the total number of toothpicks is equal to 3 + 3 or 3 x 2. The total number of toothpicks in figure 3 is equal to 3 + 3 + 3 or 3 x 3. The total number of toothpicks in figure 4 is equal to 3 + 3 + 3 + 3 or 3 x 4. To help participants acquire this algebraic insight, suggest that they try representing Pattern A in a vertical table like that in Anju and Marlena's work. In that table, the first column is labeled n, the position of the figure, and the second column is labeled t, the number of toothpicks in the figure.
Most participants will notice the recursive rule first. They may describe the rule as “+3” or “add 3.” The challenge for participants may be moving from the recursive rule to the algebraic rule. The recursive rule involves adding 3 to get the next number in the pattern, but the algebraic rule involves multiplying the position number, n, by 3. For example, figure 2 in Pattern A is made up of 2 triangles each with 3 toothpicks, so the total number of toothpicks is equal to 3 + 3 or 3 x 2. The total number of toothpicks in figure 3 is equal to 3 + 3 + 3 or 3 x 3. The total number of toothpicks in figure 4 is equal to 3 + 3 + 3 + 3 or 3 x 4. To help participants acquire this algebraic insight, suggest that they try representing Pattern A in a vertical table like that in Anju and Marlena's work. In that table, the first column is labeled n, the position of the figure, and the second column is labeled t, the number of toothpicks in the figure. 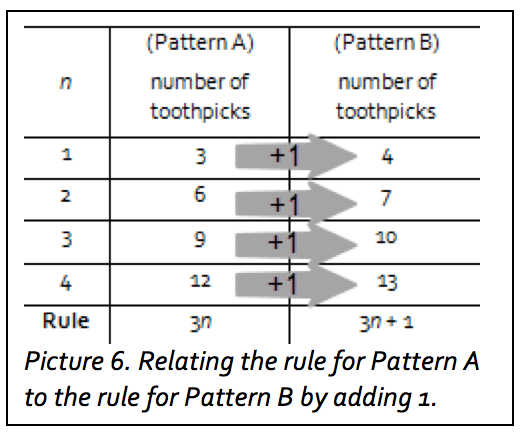 Encourage participants to consider how the numbers in the n column are related to the numbers in the t column. This arrangement may make it easier for participants to see that the number of toothpicks for each figure in Pattern A is 3 times the value of n (the position of the figure). Participants may simply note this or may be able to use it to write 3n, which is the algebraic rule for Pattern A. Finding the algebraic rule for Pattern B is less obvious, however. One way to help participants explore this is to have them draw a third column for the same table and list the number of toothpicks in Pattern B in that table. As shown in Picture 6, placing the two patterns side by side can help participants compare the numbers of toothpicks in Pattern A to the numbers of toothpicks in Pattern B and notice that the values for Pattern B are all 1 more than the corresponding values for Pattern A. So, 1 can be added to the algebraic rule for Pattern A to find the algebraic rule for Pattern B. The algebraic rule for Pattern A is 3n. So, the algebraic rule for Pattern B is 3n + 1.
Encourage participants to consider how the numbers in the n column are related to the numbers in the t column. This arrangement may make it easier for participants to see that the number of toothpicks for each figure in Pattern A is 3 times the value of n (the position of the figure). Participants may simply note this or may be able to use it to write 3n, which is the algebraic rule for Pattern A. Finding the algebraic rule for Pattern B is less obvious, however. One way to help participants explore this is to have them draw a third column for the same table and list the number of toothpicks in Pattern B in that table. As shown in Picture 6, placing the two patterns side by side can help participants compare the numbers of toothpicks in Pattern A to the numbers of toothpicks in Pattern B and notice that the values for Pattern B are all 1 more than the corresponding values for Pattern A. So, 1 can be added to the algebraic rule for Pattern A to find the algebraic rule for Pattern B. The algebraic rule for Pattern A is 3n. So, the algebraic rule for Pattern B is 3n + 1.
Extensions
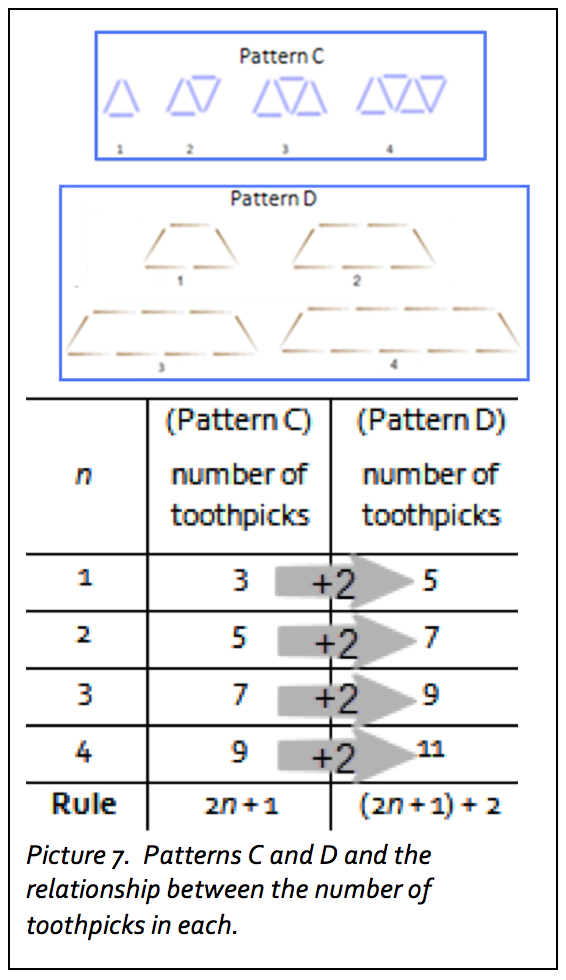
Depending on the comfort level of your participants, you can then present Patterns C and D, which are shown in Picture 7. If participants realize that the rules for Patterns A and B are related, it may change the way they approach Patterns C and D. Although these two patterns look dissimilar, both involve adding 2 toothpicks to a figure to form the next figure. It may take some time and trial and error for participants to determine the algebraic rule for Pattern C, 2n + 1. However, if they set up a table like the one in Picture 5, they may notice that each figure in Pattern D has 2 more toothpicks than its corresponding figure in Pattern C. Therefore, if the algebraic rule for Pattern C is 2n + 1, the rule for Pattern D is (2n + 1) + 2 or 2n + 3.
Reflections and Group Share
Ask participants to reflect on their individual experiences. You can have them write freely or give them a question, such as, “How did you or your group go about exploring the patterns and trying to figure out the rules?”
After individuals have had a chance to reflect, bring the whole group back together and ask them to share their reflections, as well as highlights and questions from their small group work with patterns. Invite participants to consider how different representations can change the way they see patterns. Discuss how you might ask young children to represent patterns in different ways – using manipulatives, drawings, tables, words, or expressions – and how it can help them deepen their understanding of patterns and algebraic thinking.
Sarama, J., & Clements, D. H. (2009). Early childhood mathematics education research: Learning trajectories for young children. New York: Routledge.
We describe a way to engage participants in learning about patterns and algebraic thinking in Teaching Algebraic Thinking to Young Children...

This activity supports teachers to consider how to use observational data to promote engagement and learning in mathematics in ways that are...

This use case explores participants’ understanding of the wide variety of patterns encountered in the preschool classroom and draws out...